



The SV Canon, AI agent interfaces, ontology, and more
We go a little AI-heavy in Issue #4 of our ongoing review series.




The Silicon Valley Canon
TANNER GREER IS BACK with another great essay, this time writing about what makes a ‘tech canon’. We’ve always been fascinated by the idea of canons, syllabi and great books; one of our very first essays was on this topic:

So naturally we dug in. Tanner starts off by exploring the reading habits of Silicon Valley techies and Washington policy wonks. There’s a bit of a fox-and-hedgehog dichotomy to their habits, with the Washington wonks being hedgehog-like in their appreciation of ‘deep but narrow learning’, and the SV folks being fox-like in their desire to be ‘conversant in as many subjects as possible’. SV folks also tend to share a huge bias for action, so they naturally gravitate towards books about big ideas and great men. Tanner puts it perfectly:
“You can divide most of these titles into five overarching categories: works of speculative or science fiction; historical case studies of ambitious men or important moments in the history of technology; books that outline general principles of physics, math, or cognitive science; books that outline the operating principles and business strategy of successful start-ups; and finally, narrative histories of successful start-ups themselves.”
— Tanner Greer, “The Silicon Valley Canon: On the Paıdeía of the American Tech Elite”
A lot of the books on the Mortimus shelf can also be put in these five categories. Looking back, it feels almost organic how we chose some of our own books, but obviously that wasn’t so. We were just collecting book recommendations from respected people in our fields. Our goal was to crank our internal learning machines to eleven, and the only way to do that was to get to baseline with the luminaries. Only later did we start exploring the edges of their knowledge and go footnote-hunting. That hunt still continues.
Tanner also perfectly nails another reason why the books in tech’s ‘vague canon’ are what they are. These books help define the characteristic spirit of the builder culture, and lay down its shared history:
To study the great men of a community’s past is to study what greatness means in that community. That I think is half the purpose of these biographies of Roosevelt and Rockefeller, Feynman and Oppenheimer, Licklider and Noyce, Thiel and Musk. These books are an education in an ethos. Such is the paıdeía of the technologists.
Canons have always been a roadmap from the past, guiding builders towards the future. Since we so often build on the shoulders of giants, these canons should not be ignored.
Anyways, here is one choice from each of the five categories (with a Mortimus spin):

In this issue:
User Interfaces for AI Agents
The need for Ontology in AI Systems
LLM Oblique Strategies
User Interfaces for AI Agents
Nikesh Arora, CEO of Palo Alto Networks, recently spoke at the All In Summit. There was a chunk later in the interview where he was asked about his thoughts on AI. Nikesh neatly summarized the overall landscape:
For consumers, we have to figure out how LLMs and AI translate to useful consumer services and make them better. Either new startups will emerge that shift our behaviour away from the incumbents, or the incumbents will embed AI into their products and get bigger.
For enterprises, AIs are useless if they cannot be trained on their internal data. But to even get to the training stage, the data needs to be cleaned and refactored. This leads us to the idea of Ontology (which we discuss in the next section in a bit more detail).
However, his discussion on the interfaces for AI Agents is a thread that’s worth pulling on. As agents become better, they will stack multiple user requests into one flow. Consider this: we ask an agent to book us a flight and tickets to a hotel in NYC. The agent interfaces with Booking.com, airline websites, hotels.com and comes back to us with a booking code and confirmation. In this example, these ‘legacy websites’ merely acted as data providers, exposing their APIs to the agent which is the only user-facing interface.
But will these big legacy providers like being a mere data provider?
Nikesh considers the arrow of progress to move in only one direction. Either these companies capitulate and make their data AI-Agent friendly, or new companies will emerge that will cater specifically to an AI-agent future. What does that bode for the future of consumer apps?
“I think there’s going to be much more upheaval in the consumer space then anyone of us realizes. I think 5 millions apps will be redesigned in the next ten years.”
Margins on these apps will go down, and so will the power of the legacy providers. Our hunch is that the interface that controls the UI will have the final say. Where that UI eventually lands, and who gets to control it — only time will tell.
Ontology: The next step for enteprise AI
This brings us to the enterprise side of the equation.
Our comments below were prompted by a video that was posted to the r/PLTR subreddit, which discusses Palantir. Michael R. Landon, a software engineer with a background in philosophy had this to say about the direction where AI is going:
Instead of … starting from AI and building it out, we need a software system that knows what things are and then adjudicates tasks, adjudicates intelligence tasks based on what things are and the logic between them. There's no guardrails to how AI works. It just, we just hope that it has intuited the information between all of the different data points, and it maybe has and maybe hasn't. No, we can't rely on [that].
We discussed AI Agents above, but for these agents to work well, they need clean data to work with. Ben Thompson puts it clearly: “the reality is that an effective Agent — i.e. a worker replacement — needs access to everything in a way that it can reason over”1. This means that agents need an accurate representation of the world they inhabit.
Which brings us to Ontology.
In the world of philosophy, ontology refers to a branch of metaphysics concerned with the nature and relations of being. In the world of computing, it is the process of formally naming the types, properties and relationships between entities.
Think about how you understand the world. You don't just see a collection of shapes and colors; you see objects, people, relationships. You understand that a chair is for sitting, that it's different from a table, that both are types of furniture. This intricate web of understanding is something we take for granted.
Current AI systems are capable of incredible feats of pattern recognition but often lack fundamental understanding. They can tell you with astonishing accuracy whether an image contains a cat, but they don't really know what a cat is, what it does, or how it relates to, say, a dog or a mouse.
That’s why ontology is important. It's about creating a structured framework that mimics how humans understand the world. In tech speak, it's “object-oriented data-based organization.” In plain English, it's teaching AI the basics of how the world fits together. Here’s Michael:
in the same way that … in the last decade, we decided to have object-oriented programming, we need … object-oriented data-based organization. And that's basically what the ontology is — saying that each of the individual pieces come together under an object, and you need to have data organized that way, and then the relationships between the actual objects themselves defined, so that way you can leverage the data in a clean way, and the inference technology that AI allows for gets amplified by the guardrails of definition and logical relationships.
Michael’s video eventually becomes a case for Palantir, which he calls the ‘sleeping giant of AI’. Palantir has been leaning into Ontology-based AI development for a while now, their CTO made comments to this effect back in 2023:
I feel like [Palantir]’s founding trauma was realizing that actually everyone claims that their data is integrated, but it is a complete mess and that actually the much more interesting and valuable part of our business was developing technologies that allowed us to productize data integration, instead of having it be like a five-year never ending consulting project, so that we could do the thing we actually started our business to do.
— Shyam Sankar, Palantir CTO (source)
When they talk about data integration, they are referring to organizing data under an ontology. It's not glamorous work. There are no flashy demos or headline-grabbing breakthroughs. It's the boring task of data cleaning, of building consistent structures, of slowly, painstakingly creating a digital mirror of the real world. But the payoff could be enormous, and systems like Palantir’s can make this process slightly easier.

Here are Michael’s closing comments, which we think round out this discussion:
You need knowledge, you need actual specific knowledge, you need understanding what things are and the logical relationships between things, because ultimately, business is a logical relationship between many parts organized towards a specific purpose, and the AI is basically the intuitive aspect that can then adjudicate certain details and make decisions. So, you have the relationships, and then you have the decision making, and that is how it all comes together. So, we need to stop thinking as AI is the solution and thinking about it as a piece of the solution in a broader context that then propels us forward.
We’ll definitely be doing a deeper dive into Ontology for AI systems in a future essay.

Mortimus Recommends:
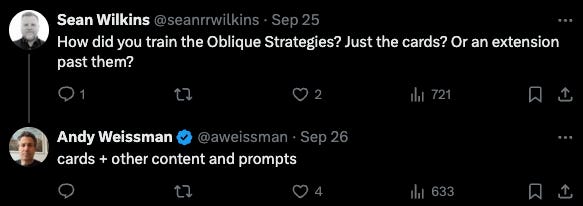
Training Oblique Strategies into an LLM: Scouring our X feed we came across this tweet by Andy Weismann of USV. Andy has created many tools within ChatGPT to help his investment process, and a surprising one was Oblique Strategies. For the uninitiated, Oblique Strategies is a “card-based method for promoting creativity jointly created by musician/artist Brian Eno and multimedia artist Peter Schmidt, first published in 1975.” Each card is a prompt, and the goal is to use it to get out of a tricky creative rut.

(source) 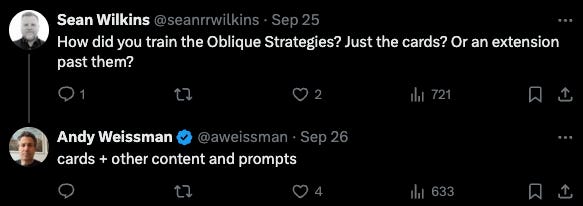
Training these cards into a chat-based interface is a great idea. An ideal use case: interleave these prompts into our writing practise. It picks up on the context of what we’ve written so far, and surfaces the 3-4 most relevant oblique strategies for us if we’re stuck.
Steven Johnson on using NotebookLM as a Research Tool (source): Steven Johnson has had a wonderful career researching and exploring where ideas come from and how we can sustain innovation. He is also part of the editorial team for NotebookLM, a tool developed by Google Labs to augment research and writing. He explains that NotebookLM’s approach is centred around “source-grounded AI” wherein “you define a set of documents that are important to your work—called ‘sources’ in the NotebookLM parlance—and from that point on, you can have an open-ended conversation with the language model where its answers will be “grounded” in the information you’ve selected.” There is also a surprisingly good podcasting feature of this tool (called Audio Overviews) where two AI hosts discuss the sources you’ve provided. It’s very useful, and even if it’s a little undercooked right now, it doesn’t take much to imagine the potential directions this can go. We recently fed all our Readwise notes into the machine, and have had fairly solid conversations so far. More to come on this.
This passage from Eliot Peper (source): “Jurassic Park inspired more people to go into biotech than any academic paper. The Matrix inspired more people to go into computer science than any GitHub repo. The Martian inspired more people to go into aerospace engineering than any industry trend report. Science fiction doesn’t predict the future, it does something much more interesting: tell stories about technology so compelling that people dedicate their lives to advancing the frontier.”
The Photos of Vivian Maier (source): Just look at these, so much life!



That’s it for this week. Onwards to Consilience!

https://stratechery.com/2024/enterprise-philosophy-and-the-first-wave-of-ai/
Player of Games is great. Have you read Use of Weapons?